Just as a musical ensemble is a collection of different instruments contributing to a single tune, ensemble modeling is multiple models used together to outperform any one of the contributing models. It is based on the philosophy that “Together, we are better.”
An excellent example of this is the competition Netflix held a few years ago. For the challenge, Netflix offered $1 million to anyone who could improve their movie recommendation algorithm by 10 percent. After three years of submissions, the prize was finally awarded to a team. How did they find their success? They were a combined team, an ensemble formed of other teams that merged their thinking and models into a single model. This approach really shines a light on the power of ensemble modeling.
We all know that models use current and past information about customers and prospects to predict future actions. This includes behaviors in regards to buying, opening, responding, churning, charging off, etc. When building a predictive model, there is a wide variety of analytical techniques to choose from that generally all produce similar results. Most modelers use well-known, common techniques for their business analytics, depending on the modeler’s experience and personal preference.
For example, many data scientists use logistic regression as a common tool to solve business problems that can be viewed in a binary manner — this includes options such as click (yes/no), churn, (yes/no), buy product A vs. B, etc. However, other techniques less often used can solve these types of problems effectively. Most notably, decision trees such as CART and CHAID, neural networks, and machine learning algorithms like SVM, are often underused.
What’s interesting is that while the different techniques produce similarly effective results, they go about their jobs in very different ways. For example, a regression-based approach seeks to find the set of predictors that collectively minimize the sum of the squared differences between actuals and projections. A decision tree, on the other hand, chooses, predicts one at a time, independently selecting the next one that provides the biggest statistically significant split in performance. In some situations, one technique is more appropriate than another, but often any one of a handful of techniques can be appropriate. On their own, each technique can provide the business a lift that drives thousands or millions of dollars in performance benefits.
But why do we have to choose only one?
Like in the Netflix challenge, when you have many points of view, you not only have a better chance of finding a solution but also are able to come up with an even better solution using parts of multiple ideas. This, in essence, is what an ensemble model is. Combining multiple, or an ensemble of, techniques to arrive at a solution that outperforms any of the solutions derived from a single technique.
Building an Ensemble Model
When I build an ensemble model, I first build a variety of individual models, each using a different technique but all working to predict the same outcome. I then use the output scores from each of the models as predictors for the second round of modeling, this time using only your preferred modeling technique. Consider the following example:
For a typical classification model, say response, we might prefer the use of logistic regression on behavioral and demographic data to best predict responders from non-responders. The validation results in Figure 1 show a nice rank order of the deciles, with decile 1 most responsive, at 27 percent, and decile 10 least responsive, at 4 percent.

Figure 1. Actual response rates from a hold-out sample (not used in the model development) split out by model decile where decile 1 is expected to have the best performance descending to decile 10 expected to have the worst performance.
Let’s test the decision-tree approach and build a CHAID model. In Figure 2, we see the logistic and CHAID model validation performance side by side. The CHAID model doesn’t rank order as well as the logistic model, going from 23 percent to 5 percent.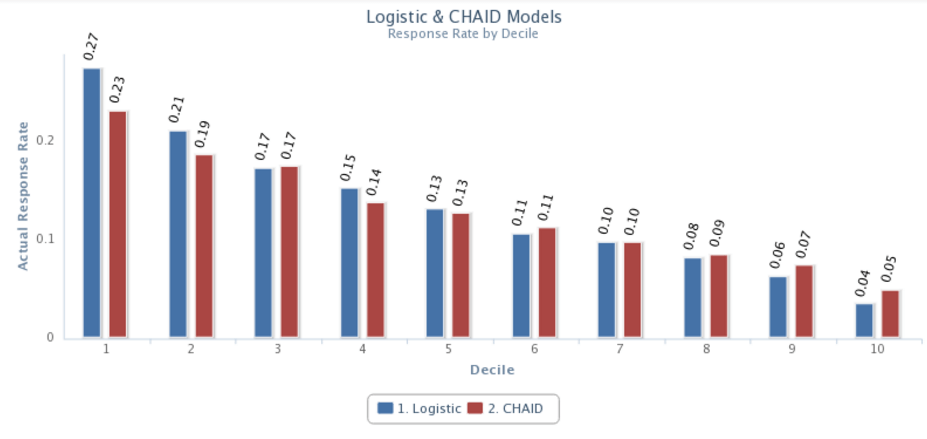
Figure 2. Use of a CHAID decision tree on this example data to separate response rates into ten deciles shows not to be as effective an approach as logistic regression. The CHAID decile response rate range (best performance subtract worst) is not as good as the Logistic response rate range.
Next, we will try an ensemble model built using a logistic regression approach on only the predicted scores of the logistic and CHAID models as inputs. Figure 3 validation results show us this. By combining the logistic and CHAID approaches, we are able to get a slightly improved model over the initial logistic model only, with the deciles of the ensemble model going from 28 percent to 3 percent.
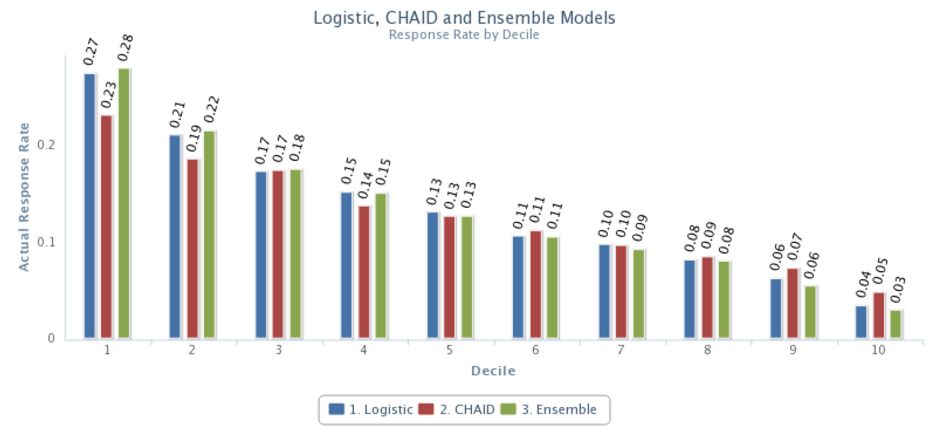
Figure 3. The Ensemble model produces a greater range in decile response rates than the Logistic (.25 vs .23) and the CHAID (.25 vs .18).
An ensemble model is not guaranteed to outperform its component models. However, when it does, it’s because there is some incremental insight that one approach was able to capture that the other was not. This is like filling in the small cracks of missing explanation that a single model approach leaves behind. These small improvements in large volumes can generate substantial, powerful gains for your business.
Ensemble modeling approaches can become very involved, but hopefully, you see the approach presented here is simple enough to warrant a review the next time you’re looking to try and get more out of your predictive modeling!


