I hate the phrase “artificial intelligence.” I use AI every day, like all of us. I invent it, but I don’t know what it is. It has become too nebulous and exaggerated thanks to people who don’t know what they are talking about (Hollywood, politicians, etc.). For the purposes of this article, I’ll be talking about machine learning (ML). See this helpful article if you’re interested in the semantic differences between ML and AI.
This graph is not going to become self-aware and kill you:

Please remember this graph next time someone says the machines are going to gain self-awareness tomorrow and kill us all. This graph is a simple form of machine learning. It is harmless, and not particularly sexy or buzz-worthy, especially since you probably learned about it in 7th-grade math.
Why am I so confident it is harmless, putting me at odds with my hero, Elon Musk?
Limitations of this graph and all ML…
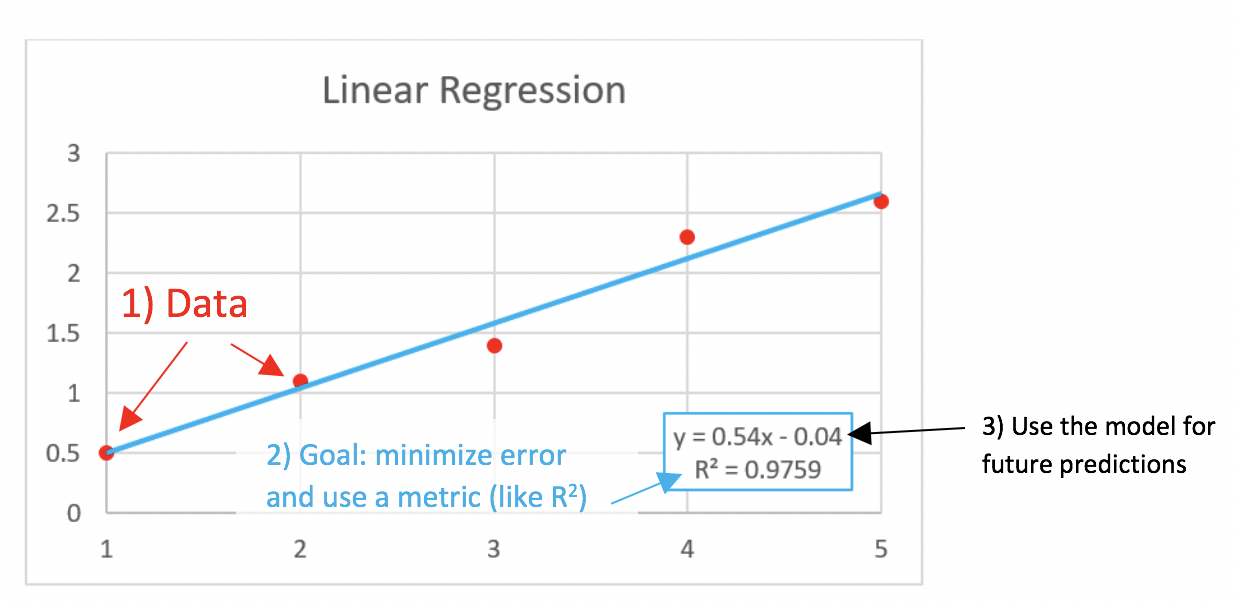
- Real world data is very messy and an incomplete picture of reality. Is there data leakage? Have you introduced errors and bias in the way you accumulated the data? (Hint: the answer is always yes.)
- How do you pick a useful metric? There is bias vs. variance considerations. Are you using cross-validation and do you have a hold-out validation set? Have you gone back and forth and tried to minimize the error so much that it is now overfit?
- How generalizable are these results? What if you have to interpolate or extrapolate beyond the given data? What if real-world conditions change and the model is total junk? Have you read Nassim Taleb’s book, “The Black Swan” and understand that your model is guaranteed to be missing huge chunks of unknown unknowns thereby making you more confident in your folly? You can put a p-value and confidence interval on your predictions, but it is total junk if the model has never come across something which is about to happen in real life. In fact, it is worse than junk, because now you have a number and you are very confident in something you shouldn’t be!
These are just the main concerns that any good data scientist considers. I’m pretty sure I’ve woken up from a nightmare before and yelled “Ahh! Data leakage! Black Swan! Validation!”.
My point is that these are challenging problems that we need humans to tackle in 2019. Our problem today is not that our models are too smart it’s that they are too dumb, and we put too much confidence in them. If you look at the 2008 collapse, or safety modeling preceding the Fukushima meltdown, you see the modelers didn’t ask Q’s from 1 – 3 enough.
Possibilities
If I have you convinced that all ML models are junk and shouldn’t be trusted, then I’ve achieved my goal. But let’s end on a positive note.
Here are some amazing examples of ML:
- No, wiretapping without a warrant still is illegal in the U.S., but if an efficient model knows that a Millennial with a particular group of friends is hanging out in a hipster part of town, combined with past buying behavior, then it will be able to make creepily-good suggestions of where to purchase beer.
- Deep Neural net predicting handwritten numbers with amazing accuracy (99.1%!).

- My personal project—predicting usage of electricity (only 25% improvement from the control).
- Lityx has been modeling for over a decade and has some examples on its blog.
- How Siri and Alexa work: ML’s are trained on a combo of speech recognition, natural language processing (NLP) and probabilities of what words usually follow other words, etc.
- How Netflix and Amazon predict what you want to purchase next: simply put, they create a massive csv (similarity matrix) which understands how correlated each item is to another item based on past buying behavior.
Notice how predicting handwritten numbers can have excellent accuracy because of its tightly defined universe of data and narrow scope, but my project in predicting human behavior with scant evidence gets poor results.
Here’s an example of how when you have a program with no limits, no boundaries, no data, no rules, free to roam and do whatever it wants, it just makes gibberish. I wrote this program out of curiosity to see what it would make- it’s a program which writes itself.
All it produces so far is a few numbers and code that is deactivated (commented out). Nobody has come from the future to assassinate me yet!
Conclusion
It doesn’t have to be either-or; ML taking over the world? It’s more like “ it depends”. Computer programs can be made to automatically grab data, learn from the data (and its mistakes), and make excellent predictions, but only if you have a competent data scientist, an amenable data universe and target, a situation not susceptible to black swan events, and a bit of luck on your side.
My hope is that moving forward, people will continue to educate themselves about the limitations and possibilities of AI/ML, and not naively underestimate people who have access to our data, or naively overestimate the capabilities of ML. If the 2016 election tampering (twitter bots, effective targeting from personal data which broke FB’s terms, etc.) taught me anything, it is that people should be more concerned with the humans behind the technology, not the technology itself.
Learn more about Lityx, here.
Lance Culnane, Ph.D. is a Senior Consultant with Lityx, LLC.
Ready to get more out of your data? Talk to an analyst to learn how Lityx can partner with you to help you assess your data management and leverage advanced analytics to improve your marketing efforts.


